Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right tool.
Agenta centralizes LLM development, enhancing collaboration and reliability through structured workflows and systematic.
Last updated: March 1, 2026
OpenMark AI evolves your AI strategy by benchmarking over 100 models on your actual task for cost, speed, and quality.
Last updated: March 26, 2026
Visual Comparison
Agenta
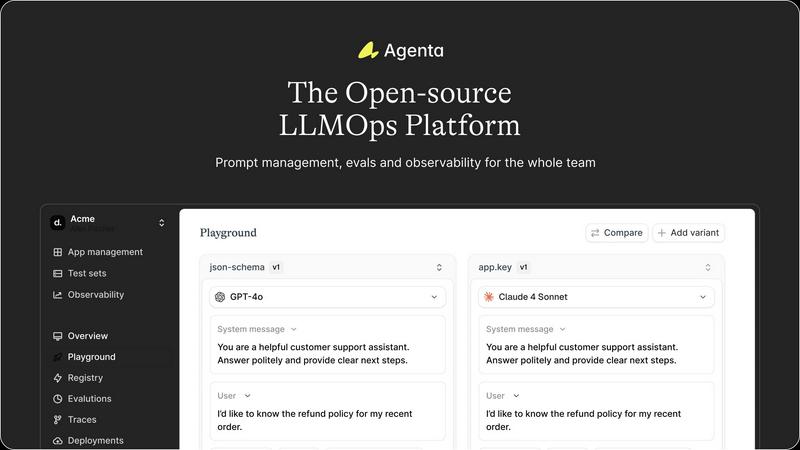
OpenMark AI

Feature Comparison
Agenta
Centralized Prompt Management
Agenta centralizes prompt storage, evaluation, and tracing within a single platform. This feature eliminates the chaos of scattered prompts across various tools, enabling teams to manage their prompts efficiently and maintain a clear overview of their work.
Automated Evaluation
With Agenta's automated evaluation capabilities, teams can create systematic processes to run experiments, track results, and validate every change made to their prompts. This feature reduces guesswork and increases confidence in the development process.
Unified Playground
Agenta provides a unified playground where teams can compare prompts and models side-by-side. This feature also allows users to save errors found in production to a test set, facilitating a seamless transition to testing and debugging.
Collaborative Workflow
The platform encourages collaboration among product managers, developers, and domain experts, allowing them to experiment, compare results, and debug prompts together. This feature enhances communication and ensures that all stakeholders are involved in the development process.
OpenMark AI
Plain Language Task Configuration
The platform begins your benchmarking journey at the most intuitive starting point: your own words. Instead of complex scripting, you describe the task you need the AI to perform—be it data extraction, creative writing, or code generation—in simple English. OpenMark AI's system validates and structures your description into executable prompts, democratizing access to sophisticated model testing and accelerating the initial setup phase from days to minutes for teams at any stage of AI maturity.
Multi-Model Comparative Analysis
This feature represents the heart of OpenMark's evolution from single-model testing to holistic comparison. You run your defined task against a large, curated catalog of 100+ models from leading providers like OpenAI, Anthropic, and Google in one unified session. The platform then presents a detailed, side-by-side results dashboard, allowing you to visually and quantitatively compare performance across cost, latency, and quality scores, transforming a complex decision into a clear, actionable dataset.
Stability and Variance Scoring
Moving beyond a single data point, OpenMark AI introduces a critical layer of maturity to benchmarking by analyzing consistency. It runs your task multiple times for each model to measure output stability. This reveals the variance in performance, showing you whether a model's first result was a fluke or a reliable indicator. This focus on repeatability ensures your product's evolution is built on a foundation of predictable AI behavior, not unpredictable luck.
Hosted Credit System & No-Code Setup
This feature dismantles the traditional barriers to entry for rigorous benchmarking. There is no need to manage separate API keys, billing accounts, or infrastructure for each model provider. OpenMark AI operates on a simple credit system, allowing you to access and test a wide array of models instantly. This no-code, no-setup approach accelerates the exploration phase, letting teams progress from idea to validated model selection without operational overhead.
Use Cases
Agenta
Streamlining AI Development
Agenta is ideal for AI development teams looking to streamline their workflows. By centralizing prompts and evaluation processes, teams can significantly reduce the time spent managing scattered resources and enhance collaboration.
Enhancing Debugging Processes
When debugging AI applications, Agenta provides tools to trace every request and pinpoint failure points effectively. This capability turns guesswork into evidence-based debugging, facilitating quicker resolutions to issues.
Facilitating Experimentation
Teams can leverage Agenta to conduct experiments efficiently by utilizing the unified playground for testing and comparing different prompts. This feature is crucial for rapid iteration and improvement of LLM applications.
Empowering Domain Experts
Agenta allows domain experts to safely edit and experiment with prompts without needing coding skills. This functionality empowers subject matter experts to contribute directly to the development process, enriching the overall quality of the AI applications.
OpenMark AI
Pre-Deployment Model Selection
When your team is ready to evolve from prototype to production, choosing the right model is paramount. OpenMark AI is used to rigorously test candidate models against the exact tasks your feature will perform. By comparing real cost, speed, and quality metrics, you make an informed, data-backed selection that balances performance with budget, ensuring a strong foundation for your shipped product.
Cost Efficiency Optimization
For growing applications, unchecked API costs can hinder evolution. This use case involves using OpenMark to find the most cost-effective model for a specific task. You benchmark to find the optimal point where output quality meets your standards at the lowest operational expense, directly impacting your product's scalability and long-term growth trajectory.
Agent Workflow and Routing Validation
As AI systems evolve into complex multi-agent workflows, routing tasks to the right model is crucial. Teams use OpenMark to benchmark different models on sub-tasks like classification, summarization, or tool-calling. The results inform routing logic, ensuring each step in an agentic chain is handled by the most capable and efficient model, optimizing the entire system's performance.
Consistency Assurance for Critical Tasks
When your application's success depends on reliable, repeatable AI outputs—such as legal document analysis or consistent brand voice generation—OpenMark's stability testing is essential. This use case involves running repeated benchmarks to identify models with low variance, guaranteeing that your user experience remains consistent and trustworthy as your product scales.
Overview
About Agenta
Agenta is an innovative open-source LLMOps platform designed to empower AI teams in developing and deploying reliable large language model (LLM) applications. The platform addresses the unpredictability inherent in LLMs by fostering collaboration between developers and subject matter experts, creating a structured environment for effective teamwork. With Agenta, teams can streamline the entire workflow of prompt management, evaluation, and observability, enabling them to experiment efficiently and validate their work with confidence. By centralizing LLM development processes, Agenta eliminates the chaos of scattered prompts and siloed efforts, allowing teams to iterate quickly and enhance performance through real-time feedback. Ultimately, Agenta serves as the single source of truth for LLM development, fostering collaboration and enhancing productivity across diverse teams, making it an invaluable tool for AI professionals aiming to build reliable applications.
About OpenMark AI
OpenMark AI is a pivotal evolution in the journey of AI development, moving teams from speculative guesswork to data-driven confidence. It is a comprehensive web application designed for task-level LLM benchmarking, built specifically for developers and product teams at the critical pre-deployment stage. The platform's core mission is to eliminate the costly trial-and-error phase of selecting an AI model by providing a controlled, comparative testing environment. You simply describe your specific task in plain language, and OpenMark AI executes the same prompts against a vast catalog of models in a single session. This process yields side-by-side results based on real API calls, not marketing datasheets, measuring critical metrics like cost per request, latency, scored output quality, and—crucially—stability across repeat runs. This focus on variance reveals a model's true reliability, not just a single lucky output. By using a hosted credit system, it removes the friction of configuring multiple API keys, allowing teams to progress rapidly from exploration to validation, ensuring the chosen model delivers optimal cost efficiency and consistent performance for their unique workflow before any code is shipped.
Frequently Asked Questions
Agenta FAQ
What is LLMOps?
LLMOps, or Large Language Model Operations, refers to the practices and tools used to manage the lifecycle of large language models, including development, deployment, and monitoring of AI applications.
How does Agenta improve collaboration?
Agenta enhances collaboration by providing a centralized platform where product managers, developers, and domain experts can work together, experiment, and share insights, breaking down silos that often hinder productivity.
Can Agenta integrate with other tools?
Yes, Agenta seamlessly integrates with popular frameworks and models such as LangChain, LlamaIndex, and OpenAI, ensuring you can use the best tools without vendor lock-in.
Is Agenta suitable for beginners?
Absolutely. Agenta is designed to be user-friendly, with features that allow even those without programming skills, such as domain experts, to contribute to prompt management and experimentation effectively.
OpenMark AI FAQ
How does OpenMark AI calculate costs?
OpenMark AI calculates costs based on the actual API pricing from each model provider (like OpenAI, Anthropic, etc.) for the prompts you run. It tracks token usage for both input and output and applies the provider's current rates. The cost shown in your results is the real expense you would incur for those API calls, providing an accurate financial comparison, not an estimate.
What is a "credit" and how does billing work?
Credits are OpenMark AI's internal currency used to execute benchmark jobs. Different models and task complexities consume different amounts of credits. You purchase credit packs through the in-app billing section. This system abstracts away the need for you to manage individual API keys and bills from multiple AI providers, simplifying the entire testing and comparison process.
Does OpenMark test models using real API calls?
Yes, absolutely. OpenMark AI performs real, live API calls to the models you select during a benchmark. It does not use cached responses or marketing numbers. This ensures the latency, cost, and quality scores in your results reflect genuine performance you can expect when you integrate the model into your own application.
Can I test my own custom prompts or evaluation criteria?
While the primary interface is designed for plain-language task description, the platform offers advanced configuration options. This allows you to input specific prompt templates, define custom evaluation instructions for scoring output quality, and set parameters to closely mirror your production environment, giving you control over the testing framework as your needs evolve.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform that supports AI teams in developing and deploying reliable large language model applications. As organizations increasingly adopt AI technologies, users often seek alternatives to Agenta due to various factors, including pricing, specific feature sets, and compatibility with existing platforms. The need for tailored solutions that align with a team's unique workflow and project requirements can drive the search for different options. When choosing an alternative to Agenta, it's essential to consider several key aspects. Evaluate the platform's ability to centralize workflow management, the robustness of its collaboration features, and the comprehensiveness of its observability tools. Additionally, understanding the support and community around the platform can significantly impact the efficiency and effectiveness of your LLM development process.
OpenMark AI Alternatives
OpenMark AI is a developer tool for task-level benchmarking of large language models. It helps teams make pre-deployment decisions by running real prompts against a wide catalog of models to compare cost, speed, quality, and output stability in a single session. Users often explore alternatives for various reasons. Some may have specific budget constraints or need features like on-premises deployment. Others might require deeper integration into existing CI/CD pipelines or seek tools focused on a different stage of the AI lifecycle, such as ongoing monitoring post-launch. When evaluating other solutions, consider your core need. Look for the ability to test with real API calls, not simulated data. Prioritize tools that measure consistency across multiple runs to see variance, and ensure they provide a holistic view that balances quality against operational cost, not just the lowest token price.