HyperLake
HyperLake evolves your AI infrastructure from human-centric dashboards to agent-driven systems with sovereign governance and zero compute markup in.
tool Details
Explore More
Alternatives
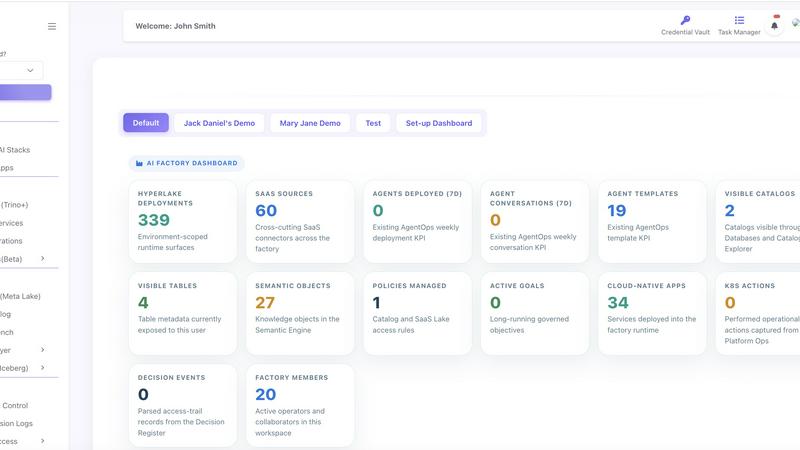
About HyperLake
HyperLake is the sovereign infrastructure command center for organizations preparing for a world where AI agents become primary consumers of enterprise infrastructure. Traditional platforms were built for humans running dashboards, reports, and scheduled queries. AI agents behave fundamentally differently: they query data continuously, call tools, trigger workflows, generate artifacts, and operate across multiple systems needing ongoing access to governed compute, data, policies, and services. HyperLake addresses this paradigm shift by providing a complete, open-stack data, analytics, semantic, workflow, and agent infrastructure deployed inside the customer’s own VPC, private cloud, or on-prem environment. The product is built for enterprises that need to deploy, manage, run, secure, and govern agentic infrastructure at scale. The broader vision extends beyond a single stack; HyperLake is designed to manage many agentic infrastructure stacks including HyperLake-native components, customer-owned cloud services, AWS/GCP/Azure-native components, open-source technologies, governed data services, workflow systems, MCP tools, and future production-ready agentic use cases. The core value proposition is making agentic infrastructure usable, secure, and production-ready end to end. Enterprises can choose their stack, deploy where their data lives, govern every human and agent interaction, audit every action, and scale new AI use cases without rebuilding the operating layer each time. With a foundation of $0 compute markup, sovereign-by-default deployment, and GitOps-managed infrastructure, HyperLake enables organizations to go live at the speed of AI while maintaining complete control over their data and operations.
Features
Unified Governance and Access Control
HyperLake provides a global policy layer that evaluates every request, whether from a human or an AI agent, against dynamic governance rules in real time. This feature enforces consistent access across all data sources, queries, and context retrieval operations. Role-based access control (RBAC) and attribute-based access control (ABAC) are combined with column masking for automatic PII redaction per role, row-level security filtering by department, region, or role, and a complete audit trail that version-tracks every action. This ensures that both human analysts and autonomous AI agents operate under the same stringent security policies.
The Traceability Loop
Every agent action, inference, query, and training run is recorded through immutable provenance logs, creating a complete traceability loop. This feature allows organizations to trace any AI decision back to its source data with full auditability. Whether an agent is exploring hypotheses, retrieving context, or generating artifacts, every step is captured and versioned. This capability is critical for compliance, debugging, and understanding how AI systems arrive at their outputs, enabling organizations to maintain trust and transparency in their agentic operations.
Data Sovereignty by Design
HyperLake enables AI agents to operate on data without moving it outside its secure environment. Sensitive information remains under full owner control through sovereign deployment patterns and confidential compute capabilities. Data sources can be federated from OLTP databases like PostgreSQL and MySQL, cloud storage services like S3, GCS, and Azure, open formats like Iceberg, Delta, and Hudi, streaming platforms like Kafka and Kinesis, and vector databases like pgVector, Qdrant, and Milvus. All data stays where it belongs while still being accessible to authorized agents and humans.
Human-Agent Symbiosis
Humans and AI agents operate on the same governed data platform with shared context and standardized memory layers. This feature allows human insight and machine intelligence to collaborate on the same datasets seamlessly. Analysts, data scientists, and engineers can work alongside autonomous and supervised AI agents, all accessing the same governed data through the same policy layer. This symbiosis enables organizations to combine human creativity and domain expertise with the speed and scale of AI-driven analysis and automation.
Use Cases
Autonomous AI Agent Operations
Organizations deploying autonomous AI agents for continuous data exploration, hypothesis testing, and iterative analysis use HyperLake as the governed system of access. Agents can query data, call tools, trigger workflows, and generate artifacts without running up unexpected compute costs, thanks to the $0 compute markup model. The platform ensures that even when hundreds of agents iterate, retry, and explore simultaneously, costs remain predictable and controlled, while every action is audited and governed.
Governed Data Access for Hybrid Teams
Enterprises with teams of human analysts, data scientists, and engineers alongside AI agents use HyperLake to provide a single governed data platform for all users. Human operators run SQL analytics, build ML models, create dashboards and reports, and develop data-as-a-service APIs, while AI agents perform autonomous retrieval, real-time context gathering, and pipeline management. The unified governance layer ensures that both humans and agents access only the data they are authorized to see.
Sovereign Deployment for Regulated Industries
Organizations in finance, healthcare, government, and other regulated sectors deploy HyperLake within their own VPC, private cloud, or on-prem environment to maintain complete data sovereignty. Sensitive data never leaves the secure environment, while agents and humans can still access and analyze it through governed interfaces. This use case is critical for compliance with data residency requirements, privacy regulations, and internal security policies.
Multi-Stack Agentic Infrastructure Management
Enterprises that need to manage multiple agentic infrastructure stacks, including HyperLake-native components, cloud-native services from AWS, GCP, or Azure, open-source technologies, and third-party tools, use HyperLake as the command center. The platform provides a unified operating layer for deploying, managing, running, securing, and governing diverse infrastructure components, enabling organizations to scale new AI use cases without rebuilding the operational foundation each time.
Frequently Asked Questions
What makes HyperLake different from traditional data platforms?
HyperLake was built from the ground up for AI agents as primary infrastructure consumers, while traditional platforms were designed for humans running dashboards and scheduled queries. The key differentiators include a $0 compute markup model that prevents unexpected costs from agent-driven workloads, sovereign-by-default deployment in your own cloud environment, a global governance layer that evaluates every request from both humans and agents in real time, and immutable provenance logging for complete traceability of every agent action.
How does HyperLake handle the compute cost problem with AI agents?
Traditional data platforms charge a markup on compute usage, which becomes problematic when AI agents generate thousands of queries in minutes. A single misconfigured agent can produce unexpected five-figure bills overnight, and at scale with hundreds of agents, costs can grow exponentially. HyperLake solves this with a $0 compute markup model, meaning you only pay your cloud provider for the underlying compute resources. This gives organizations the freedom to experiment and innovate without fear of the invoice.
Can HyperLake be deployed in my existing cloud environment?
Yes, HyperLake is designed for deployment inside your own VPC, private cloud, or on-prem environment. It supports major cloud providers including AWS, GCP, and Azure, as well as private infrastructure. The deployment is managed through Infrastructure as Code (IaC) and GitOps practices, ensuring that your infrastructure is reproducible, version-controlled, and auditable. This sovereign deployment model ensures that your data remains under your control at all times.
What types of data sources does HyperLake support?
HyperLake supports a wide range of data sources including OLTP and RDBMS systems like PostgreSQL and MySQL, cloud storage services such as S3, GCS, Azure, and R2, open table formats like Iceberg, Delta, and Hudi, streaming platforms including Kafka and Kinesis, over 100 SaaS and API connectors, and vector databases like pgVector, Qdrant, and Milvus. All data sources are federated through the HyperLake unified data layer and governed by the same policy engine.
Similar to HyperLake
Distro
Distro is an AI Distribution Operator for B2B teams and agencies. It helps you publish content, find buyer conversations, engage high-intent prospects
Polymarket Trading Bot For Crypto
Polymarket Trading Bot For Crypto
Tuning Engines
Tuning Engines evolves every AI interaction through one secure, governed API that optimizes cost, policy, and performance at every stage.
Minded
Minded empowers teams to effortlessly train AI agents to handle tasks, enhancing productivity and customer service in just minutes.

Klaws
Klaws is your 24/7 virtual agent that learns, remembers, and automates tasks across your favorite apps while you sleep.

Playwriter
Playwriter empowers agents to control their existing Chrome browser with full Playwright capabilities without the limitations of headless instances.

Patrivox
Patrivox transforms your archives into searchable treasures in minutes using advanced AI technology for effortless.

Stable Commerce
Launch a fully optimized online store in under two minutes with one AI prompt.